Wo wir herkommen
Dieser Artikel ist die direkte Fortsetzung meines Wakü-Builds im FormD T1: derselbe Ryzen 7600X, mittlerweile delidded und auf Direct-Die, dasselbe 12-Liter-Case, dasselbe selbst geschriebene ΔT-Cockpit auf dem Desktop. Thermisch war das Thema durch. Was blieb, war die andere Stellschraube: die Spannung.
Moderne CPUs laufen ab Werk mit einem Sicherheitspolster auf der Spannungskurve — so viel, dass auch das schwächste Exemplar der Serie überall stabil ist. Über den Curve Optimizer lässt sich dieses Polster pro Kern abschmelzen: weniger Spannung bei gleichem Takt heißt weniger Verbrauch, weniger Abwärme, und im Boost hält der Chip seinen Takt länger. Im 12-Liter-Case ist jedes eingesparte Watt doppelt wertvoll, weil es gar nicht erst weggekühlt werden muss.
Die Frage ist nur: Wie weit runter? Und genau an dieser Frage bin ich auf dem klassischen Weg erst einmal ordentlich gescheitert.
Der klassische Weg — und warum er lügt
Das Standardrezept lautet: Offset setzen, Stresstest laufen lassen, bei Stabilität tiefer, bei Absturz zurück. Habe ich gemacht, und zwar gründlich — jeder Kern einzeln isoliert, mit y-cruncher gezielt auf genau einen Kern gepinnt. Das Ergebnis sah großartig aus: Die sechs Kerne vertragen unter Last zwischen −26 und −50 Counts, der schwächste Kern hält nur etwa die Hälfte dessen aus, was die stärksten wegstecken. Mit zwei Counts Sicherheitsmarge habe ich das Profil angewendet, eine All-Core-Validierung lief sauber durch. Fertig, dachte ich.
Zwei Tage später fror der Rechner ein. Nicht unter Last — beim Nichtstun.
Der Mechanismus dahinter: Unter Volllast ziehen alle Kerne Strom, die Spannungsversorgung ist „steif“, der Takt moderat. Im Idle dagegen springt ein einzelner Kern für einen Hintergrundprozess kurz auf maximalen Boost — aus dem Tiefschlaf, bei fast keiner Last auf den anderen Kernen. Genau in diesen Übergängen kippt ein zu aggressiver Offset. Und es kommt noch schlimmer: Diese Abstürze sind verzögert und selten. Ein Wert kann zwei Wochen unauffällig laufen und erst dann kippen, wenn zufällig die eine seltene Konstellation auftritt. Das Feedback-Signal ist ein Ja/Nein mit tagelanger Latenz.
An dieser Stelle muss ich kurz deutlich werden: Genau das macht Curve-Optimizer-Undervolting zu einer der undankbarsten Disziplinen am PC überhaupt. Beim klassischen Overclocking gibt es ein eingespieltes Ritual — Takt hoch, Benchmark drauf, und ein zu hoher Takt crasht reproduzierbar: im selben Test, meist innerhalb von Minuten. Man bekommt sofort Feedback, kann den Fehler gezielt nachstellen und weiß genau, wann man fertig ist. Beim CO-Undervolt existiert dieses Ritual schlicht nicht. Der empfindlichste Zustand — niedrige Last, ein einzelner Kern springt auf maximalen Boost — lässt sich mit keinem Benchmark der Welt gezielt provozieren. Der Fehler tritt auf, wann er will: beim Tab-Wechsel, beim Start eines Hintergrunddienstes, nachts im Leerlauf. Diese Nicht-Reproduzierbarkeit ist der eigentliche Gegner dieses Projekts — und der Grund, warum die Lösung nicht „besser testen" heißen kann, sondern nur: den Alltag selbst zum Test machen.
Man kann dagegen anstresstesten, so viel man will — die Werkzeuge testen Last, nicht Leben. Nach dem zweiten Idle-Freeze mit einem „validierten“ Profil habe ich die Konsequenz gezogen: Wenn der Alltag die einzige ehrliche Testbench ist, dann muss der Alltag die Suche übernehmen.
Die Idee: Jeder Neustart ist eine Iteration
Der Gedanke ist simpel: Ein Rechner wird ohnehin regelmäßig neu gestartet — ein- bis dreimal am Tag. Jede Sitzung zwischen zwei Neustarts ist ein Langzeittest unter echten Bedingungen: Spiele, Renderjobs, Browser, Leerlauf über Nacht. Wenn ein System diese Information systematisch einsammelt, hat es genau das Signal, das dem Stresstest fehlt.
Also läuft die Suche jetzt so: Bei jedem Boot wendet ein Hintergrunddienst den nächsten Kandidaten-Wert an. Übersteht die Sitzung ohne Absturz, gilt der Schritt als bestanden und der nächste wird etwas mutiger. Gab es einen Crash, geht es konservativer zurück. Der Suchfortschritt lebt in einer JSON-Datei und überlebt jeden Absturz — der Rechner tastet sich über Wochen von selbst an sein persönliches Minimum heran.
Die Architektur
Drei Teile spielen zusammen. Ein Daemon läuft als SYSTEM-Task ab Boot. Ein Suchalgorithmus (Python) entscheidet aus dem Ausgang der letzten Sitzung den nächsten Schritt. Und das Cockpit — dasselbe ΔT-Panel aus dem Wakü-Artikel — zeigt den Live-Zustand und enthält genau einen Knopf.
Das wichtigste Bauteil ist dabei ausgerechnet das langweiligste: die Gnadenfrist. Nach jedem Boot bleibt die CPU erst einmal 120 Sekunden auf Werkseinstellung, erst dann wird der Kandidat angewendet. Das klingt banal, verhindert aber das Horrorszenario jedes automatischen Undervolts: die Boot-Schleife, in der ein instabiler Wert sofort nach dem Start wieder anliegt und der Rechner crasht, bevor man eingreifen kann. Mit der Gnadenfrist hat man nach jedem Absturz zwei ruhige Minuten — mehr braucht es nicht.
Die Absturzerkennung läuft doppelt: Ein unsauberer Neustart hinterlässt im Windows-Eventlog ein Kernel-Power-41-Ereignis, das der Daemon beim nächsten Boot automatisch auswertet. Und für alles, was das Eventlog nicht sieht — Freezes, hartnäckige 0,5-GHz-Hänger — gibt es den CRASH-Knopf im Cockpit. Er ist die gesamte Bedienoberfläche. Man drückt ihn nur, wenn es wirklich gekracht hat; den Rest der Zeit fasst man nichts an.
Die Suche: Bisektion mit Schuldzuweisung
Das Herzstück der Suche ist ein uraltes Prinzip: die Bisektion. Jeder kennt sie vom Zahlenraten-Spiel: Ich denke mir eine Zahl zwischen 1 und 100, du rätst, ich sage nur „höher" oder „tiefer". Wer clever spielt, rät immer die Mitte des verbleibenden Bereichs — und braucht damit höchstens sieben Versuche, egal welche Zahl ich mir ausgedacht habe. Der Trick: Jede Antwort halbiert den Suchbereich, statt ihn nur um eins zu verkleinern.
Genau dieses Spiel spielt der Autopilot gegen die Physik. Für jeden Kern gibt es einen Korridor zwischen zwei Grenzen: oben der letzte Wert, der nachweislich stabil lief (anfangs 0, also Werkszustand), unten die tiefste Absenkung, die überhaupt in Frage kommt. Jede Sitzung ist ein Rateversuch in der Mitte dieses Korridors. Übersteht der Rechner die Sitzung, wird die untere Hälfte des Korridors weiter erkundet — der Wert war ja gut, es geht also noch tiefer. Kracht es, war die Mitte zu viel, und die Suche zieht sich in die obere, sichere Hälfte zurück. So sieht das für einen einzelnen Kern aus:
Das ist der Grund, warum die Suche überhaupt in realistischer Zeit fertig wird. Ein Korridor von 40 Counts wäre in Einer-Schritten erst nach 40 Sitzungen durchprobiert — die Bisektion kreist dasselbe Limit in vier bis sechs Sitzungen ein. Bei ein bis drei Neustarts pro Tag ist das der Unterschied zwischen einem Monat und einem halben Jahr.
Der Autopilot bisektiert dabei gleich in zwei Richtungen: einmal im Wertebereich (wie tief darf der Offset?), und einmal in der Menge der Verdächtigen (welcher Kern war schuld?). Sechs Kerne einzeln nacheinander auszutesten würde trotz Bisektion Monate dauern. Stattdessen arbeitet die Suche in Phasen. In der Gruppen-Phase werden die Kerne in zwei Dreiergruppen geteilt, die abwechselnd tiefer gesetzt werden — pro Schritt ändert sich immer nur eine Gruppe. Der Trick: Kracht es, ist sofort klar, welche Hälfte schuld war. Der Verdächtigenkreis halbiert sich mit jedem Crash.
In der Feintuning-Phase wird dann jeder Kern einzeln an sein Limit geführt — hier ist die Zuordnung eines Absturzes eindeutig. Und in der Bestätigungs-Phase muss das fertige Profil sechs Sitzungen in Folge ohne Absturz überstehen, bevor es als stabil gilt. Jeder Crash setzt den Zähler zurück.
Der härteste Fall ist der verzögerte Absturz in der Bestätigungs-Phase: Es wurde nichts verändert, und trotzdem kracht es — irgendein Kern lag eben doch zu knapp. Ein naives System würde den zuletzt angefassten Kern beschuldigen und endlos danebenjustieren. Hier passiert stattdessen Statistik: Zurückgenommen wird der am wenigsten bewährte Kern — der mit den wenigsten überstandenen Sitzungen. Häufen sich die Crashes trotzdem, greift ein Notnetz und nimmt alle sechs Kerne gemeinsam eine Stufe zurück. Das garantiert eine angenehme Eigenschaft: Jeder Absturz macht das Profil strikt vorsichtiger, nie aggressiver. Die Crashes können nur monoton seltener werden.
COnxt: Sehen, wohin die Reise geht
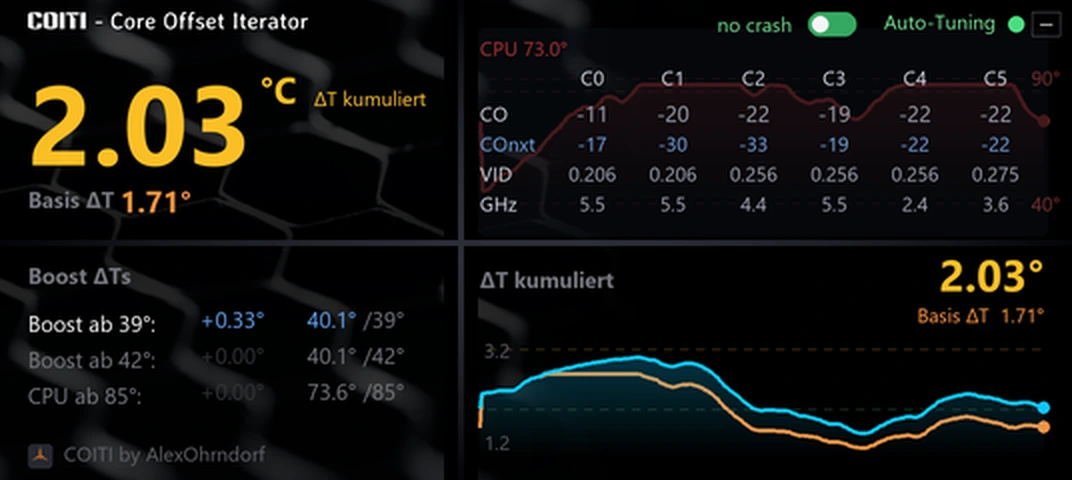
Im Cockpit zeigt die Kerntabelle vier Zeilen: CO (aktueller Core Offset), COnxt (Core Offset next), VID (angeforderte Spannung) und GHz. Die COnxt-Zeile ist mein Lieblingsdetail: Sie zeigt die Offsets, die das System nach dem nächsten sauberen Neustart anwenden wird. Berechnet wird das, ohne irgendetwas zu verändern — der Suchalgorithmus simuliert auf einer Kopie seines Zustands ein „Sitzung bestanden“ und verrät, was er dann täte. Man sieht der Maschine beim Planen zu.
Genau dieser Blick aufs Hero-Bild oben: Aktuell liegen beide Gruppen auf halber Absenkung (−11/−20/−22/−19/−22/−22), und COnxt kündigt an, dass Gruppe 0–2 beim nächsten Boot auf −17/−30/−33 nachschärft. Kein Menü, kein Neustart ins BIOS, kein manuelles Protokollführen.
Wie lange dauert das?
Ehrliche Antwort: Bei verzögerten Abstürzen gibt es keine Zahl, die hundertprozentige Sicherheit bedeutet — nur wachsendes Vertrauen mit jeder sauberen Sitzung. Um einen Kern, der im Schnitt jede elfte Sitzung kippen würde, mit 99 % Sicherheit zu überführen, braucht es rechnerisch rund 48 absturzfreie Sitzungen. Suche, Bestätigung und ein paar Korrekturen zusammengerechnet lande ich bei 80 bis 150 Neustarts bis zum belastbar bestätigten Minimum — bei normaler Nutzung ein bis drei Monate. Das Schöne: Schon nach 30 bis 40 Neustarts steht das Profil meist weitgehend richtig. Der lange Rest ist reines Sammeln von Gewissheit, und davon merkt man im Alltag nichts.
Die Suche läuft seit dem 11. Juni scharf. Iteration 1 ist ohne Absturz durch, Iteration 2 läuft gerade. Der Rechner wird jetzt von selbst, Woche für Woche, ein Stück effizienter — und ich fasse dafür genau dann etwas an, wenn er abstürzt: einmal CRASH drücken, fertig.
Fazit und Ausblick
Der eigentliche Erkenntnisgewinn dieses Projekts war nicht der Algorithmus, sondern die Demut davor, was „stabil“ bedeutet. Stresstests beantworten die Frage „hält der Wert unter Last?“ — aber das ist nicht die Frage, die zählt. Die zählende Frage lautet „hält der Wert mein echtes Leben aus?“, und die kann nur das echte Leben beantworten. Sobald man das akzeptiert, ist der Rest fast zwangsläufig: Persistenz über Reboots, eine Gnadenfrist gegen Boot-Schleifen, konservative Schuldzuweisung bei unklaren Crashes.
Einen Namen hat das Ganze inzwischen übrigens auch: COITI — der Core Offset Iterator. Wer bei der Aussprache an etwas anderes denken muss: Das System und der Rechner kommen sich über die Wochen eben wirklich sehr nahe.
COITI ist aktuell eng mit meinem Setup verzahnt — es hängt am AquaOLED-Cockpit und ist auf den 7600X zugeschnitten. Grundsätzlich steckt aber nichts darin, was nicht auf jedem Ryzen liefe: ein Boot-Task, ein Suchzustand in JSON, ein Tray-Knopf. Ob daraus ein eigenständiges Tool mit Installer wird, hängt allein davon ab, ob es außer mir jemand haben will. Falls du COITI auf deinem Rechner laufen lassen willst: Schreib es unten in die Kommentare oder meld dich direkt. Genug Interesse — und ich baue den Installer.
Update 15. Juni: Erst kam die unbequeme Erkenntnis
Ein paar Tage Alltag mit dem scharfen Autopiloten haben mir eine Lektion verpasst, die ich hier ehrlich aufschreibe, weil sie das ganze Projekt geerdet hat: Der Rechner ist auch dann hart neu gestartet, als gar kein Undervolt aktiv war — bei Werkseinstellung, null Offset. Damit war eine bequeme Annahme vom Tisch. Nicht jeder Kernel-Power-41 ist „der böse Undervolt“. Manche Reboots haben andere Ursachen — Netzteil, Speicher-Profil, Treiber, im Zweifel auch mal ein Kind am Power-Knopf.
Genau dahin hat sich der Fokus verschoben: weg vom „letzten Count Spannung“, hin zu Robustheit und Beobachtbarkeit. Ein Autopilot, der unbeaufsichtigt über Wochen sucht, ist nur so gut wie sein Verhalten im schlechtesten Moment. Also habe ich den schlechtesten Moment durchgespielt — und das Sicherheitsnetz so lange verstärkt, bis es jeden Fehlerfall abfängt.
Das Sicherheitsnetz, dreifach geknüpft
Drei Schutzmechanismen sorgen jetzt dafür, dass COITI sich nicht selbst in eine Ecke manövrieren kann:
1 · Kein Boot-Crash-Loop. Stürzt ein festes Profil zweimal in Folge hart ab, stuft COITI automatisch herunter — von „aggressiv“ auf „mild“, von „mild“ auf „Werkszustand“. Ein crashendes Profil wird also nie endlos neu angewendet; der Rechner kann sich aus eigener Kraft in den sicheren Hafen zurückziehen.
2 · Kein endloses Hin und Her. Falls die Limp-Erkennung (dazu gleich) mehrfach hintereinander anschlägt, deckelt ein Zähler die Rettungsversuche: nach vier Runden setzt das System auf Werkseinstellung und rastet ein — keine weitere automatische Aktion bis zum nächsten Neustart. Das tötet die klassische „der-Bot-dreht-durch“-Schleife, in der ein Werkzeug zwischen zwei halbgaren Zuständen oszilliert.
3 · Keine Rettung, wenn nichts kaputt ist. Der unangenehmste Bug der ganzen Woche: Die Limp-Recovery sprang auch dann an, wenn die CPU völlig gesund war — und „reparierte“ etwas, das nicht kaputt war, wodurch der Undervolt sinnlos verwässerte. Die Lösung ist ein Gate mit echter Gegenprobe: Bevor irgendetwas verstellt wird, legt COITI kurz Last an und schaut, ob die CPU boosten kann. Kann sie es, liegt kein Limp vor — und die Rettung wird übersprungen. Live nachgewiesen: manueller Auslöser bei boostender CPU → „kein echter Limp, übersprungen“. Genau so soll es sein.
Der Limp-Clock — der eigentliche Endgegner
Damit Punkt 3 Sinn ergibt, muss ich das fieseste Phänomen erklären, das mich dieses Projekt gelehrt hat. Zen-4-CPUs haben eine Schutzklemme tief in der Firmware: Wird ein einziger Kern instabil, klemmt der Chip nicht etwa diesen Kern — er drosselt die komplette CPU auf rund 0,5 GHz. Der ganze Rechner kriecht dann im Sirup, obwohl die Auslastung bei lächerlichen 8–11 % liegt. Nicht die Last ist der Flaschenhals, sondern der Takt. Tückisch daran: Es ist kein Absturz, den ein Eventlog meldet — der PC „läuft“ ja. Er ist nur unbenutzbar langsam.
COITI erkennt das inzwischen zuverlässig (kurze Lastprobe statt Bauchgefühl), hebt dann Kern für Kern die Spannung an, bis die Klemme aufgeht, und sperrt den entlarvten Kern mit Sicherheitsmarge. Schon einmal live passiert: Mitten in einer Sitzung der 0,5-GHz-Einbruch → erkannt → Kern für Kern hoch → Kern 5 als Schuldiger überführt und gesperrt. Komplett von allein, ich musste nichts tun.
Vom Suchlauf zum Cockpit
Aus dem stillen Hintergrunddienst mit einem einzigen CRASH-Knopf ist eine kleine Kommandobrücke geworden — bewusst minimalistisch, vier Knöpfe, alle im freien Feld neben der Kerntabelle, keiner verdeckt eine Messkurve:
- UV — grün, wenn der Undervolt aktiv ist; rot durchgestrichen, wenn aus. Ein Klick ist der Not-Aus: Spannung sofort zurück auf Werkseinstellung.
- L — löst eine Limp-Rettung von Hand aus (leuchtet, solange sie läuft) — jetzt abgesichert durch die Gegenprobe von oben, damit ein Fehlklick nichts kaputtmacht.
- Arzt-Kreuz — der Crash-Doktor: liest nach einem Programm-/Spiele-Absturz das Windows-Eventlog aus, nennt das abgestürzte Programm samt wahrscheinlicher Ursache (Treiber-Reset, OpenGL-Hänger, Hardware-Fehler) und legt einen Report ab.
- G — der bekannte Game-Mode.
Dazu zwei Dinge, die COITI ehrlicher machen: Es führt jetzt ein eigenes Logbuch mit Zeitstempeln — jeder Klick, jeder Zustandswechsel — und hat eine Eingabezeile. Fällt mir im Alltag etwas auf, tippe ich es direkt ins Cockpit; die Notiz landet mit Zeitstempel im Log und wird später abgearbeitet. So sammelt das Tool seine eigene Entwicklungsgeschichte ein, ohne dass ich nebenher Protokoll führen muss.
Und der Verbindungs-Flacker, der mich lange genervt hat, ist weg: Während COITI kurz die Sensorik anhält, um die Spannung zu schreiben, zeigt es jetzt gelb „wird gesetzt“ statt fälschlich rot „offline“. Ein echter Verbindungsverlust bleibt rot — das Warnsignal lügt nicht, es unterscheidet nur ehrlich.
Und jetzt der eigentliche Clou: gebaut von einem KI-Team
Das alles oben — die drei Schutznetze, die Limp-Gegenprobe, das Cockpit, das Logbuch — ist an einem einzigen Tag entstanden, und zwar nicht von mir allein an der Tastatur, sondern von einem Team aus KI-Agenten, die sich gegenseitig kontrolliert haben. Ein Agent baut (in einer abgeschotteten Trockenübung, ohne das laufende System anzufassen). Ein zweiter Agent spielt Red Team: Er versucht gezielt, den Code zu brechen, und meldet Defekte zurück. Ein dritter nimmt das Bedien-Design ab — Größen, Abstände, Lesbarkeit. Das Ganze in Runden, bis alle drei grün geben.
Zum Schluss kam ein frischer Crash-Resistance-Audit durch zwei unabhängige Agenten: Beide haben den Code in der Trockenübung systematisch auseinandergenommen — Endlosschleifen, Boot-Schleifen, Wettlaufsituationen beim gleichzeitigen Schreiben von Statusdateien. Urteil: crash-resistent. Zwei echte Datenrennen und ein Timing-Detail, die sie gefunden haben, wurden direkt gefixt und nachgeprüft. Konzept, Code, Test, Design-Abnahme, Audit — alles KI-getrieben, an einem Nachmittag. Für mich war das der eigentlich beeindruckende Teil dieser Woche.
Wo steht COITI also heute? Es läuft stabil mit einem moderaten Profil, startet nach jedem Reboot von selbst wieder (an einem realen Crash-Reboot bereits bewiesen) und ist gegen seine eigenen Fehlerfälle abgesichert. Der nächste Schritt ist, den eigentlichen Suchalgorithmus auf diese neue, ehrlichere Grundlage zu heben — diesmal mit dem Wissen, dass nicht jeder Reboot dem Undervolt anzulasten ist.
Changelog
Dieses Projekt entwickelt sich weiter — hier halte ich fest, was sich wann geändert hat.
- 15.06.2026 — Großes Robustheits-Update: dreifaches Sicherheitsnetz (kein Boot-Crash-Loop, gedeckelte Rettungsversuche, Limp-Gegenprobe gegen Fehlauslösung). Aus dem CRASH-Knopf wurde ein Cockpit mit vier Knöpfen (Not-Aus, Limp, Crash-Doktor, Game-Mode), Selbst-Logbuch + Eingabezeile, „wird gesetzt“-Maske gegen Verbindungs-Flacker. Persistenz über Reboots an echtem Crash bewiesen. Entwickelt + auditiert von einem KI-Agententeam. Erkenntnis: harte Reboots treten auch bei Werkseinstellung auf → Undervolt ist nicht die alleinige Ursache.
- 12.06.2026 — Dieser Artikel. Architektur (Daemon, Suche, Cockpit), Bisektion mit Schuldzuweisung, COnxt-Vorschau, Gnadenfrist gegen Boot-Schleifen.
- 11.06.2026 — Adaptive Suche scharf geschaltet: jeder Neustart = eine Iteration, Suchzustand persistent in JSON.
Kommentare
Noch keine Kommentare — schreib den ersten!